

There is a big, but quiet, problem happening at high-traffic service environments like call centers or busy retail stores. These places now collect a lot of information, or data, from their customers, but this huge amount of data is actually causing a problem. Staff members have to look at low-loading screens, and customers have to wait even longer.
The problem isn’t a lack of computing power. It’s architecture. Most organizations built their queue management infrastructure on the assumption that more data automatically means better decisions. But overloaded data pipelines create bottlenecks that degrade the very real-time performance these systems were meant to deliver.
In this blog, we will talk about how managing correct data can help organizations serve customers seamlessly with personalized services without affecting operations.
The Real Reason Data Load is Slowing Down Queue Performance
Most of the time, operations leaders think the problem is the computers or machines (hardware). They believe the machines are just too slow when the waiting lines, or queue systems, start to lag. But they are actually looking for the cause of the problem in the wrong spot.
Here are a few reasons behind:
The hidden operational cost of heavy data flow
Every piece of data your system handles that is not needed causes problems. If the screens are slow, staff cannot react quickly to changes. Customers see the waiting lines freeze and lose trust in the system. They then go up to the counter to check, which makes the lines even worse. Staff make up their own ways to work, and managers cannot see what is really happening. This is a problem of trust, not just a technical issue.
Why “collect everything” is no longer the winning strategy
People used to think they had to save all data because they might need it later. Back then, saving space (storage) was a big problem.
Now, the problem is processing speed. Too much unnecessary data makes it hard to find the important information. Smart leaders know that being fast is better than having everything. Getting critical facts instantly is better than having huge datasets that load slowly. In waiting lines, just a few seconds can make a customer leave.
Common misconceptions leaders still believe
Let’s address three assumptions that executives constantly complain about:
- More data does not mean better decisions; speed and relevance do. A fast, simple number is better than a late, big report.
- Second, slow lines are usually caused by bad system design, not slow computers. Adding more computers does not fix the root problem.
- Third, for quick work decisions, being fast and mostly right is always better than being slow and perfectly accurate.
Smart leaders focus on being fast over having every tiny detail. In service lines, being able to process key information instantly is what makes customers stay.
How Modern Queue Platforms Reduce Data Load Without Compromising Visibility
The smartest organizations are not hiding information just to speed things up. They are cutting the data load by a large amount (40% to 60%) and making the data flow more smartly. Here’s how:
Event-driven data flow replacing constant polling
Old queue systems waste energy by constantly asking, “Has anything changed?” even when nothing has.
Event-driven architecture is much smarter and only sends data when something important actually happens, like
- when a new customer joins
- a service completes
- a staff member logs in
This change can cut server requests by 50% to 70%. The system stays fast but only works when needed. It is like getting a phone alert when mail arrives instead of checking the mailbox all the time.
Smart compression & optimized data packets
Traditional queue platforms were not made to scale. They send all the data every time something changes. This works for one place, but it makes systems very slow across many branches.
New systems only send the small changes in the data. For example, if the line goes from 12 to 11, the system only sends the number “minus one.” This smart way of sharing data lets big companies grow without their systems breaking down.
Edge-level processing powering faster queue decisions
Edge computing does the work locally, right at the branch.
When a customer arrives, the local system instantly calculates wait times and staff needs. It does not wait for a central server. This keeps lines running smoothly, even if the internet is slow. This quick, local process also makes data more accurate by avoiding time errors caused by delays.
Here’s what Singapore’s one of the largest retail chains noticed after switching to a smart and fast queue system:
FairPrice, Singapore’s most loved retail chain with over 370 outlets, was experiencing 30-second dashboard delays during weekend traffic. After implementing Qwaiting’s event-based data architecture and edge processing software, they reduced server load by 43% while cutting refresh times to under 2 seconds, even during Black Friday peaks.
How Smart Analytics Help Organizations Reduce Data Load
Analytics doesn’t have to mean data obesity. In fact, the best analytics frameworks are deliberately lean.
Here’s how smart analytics help organizations reduce data load by 60%:
Prioritizing only action-driving metrics
You often see too many numbers, or metrics, on the screens that service staff use. These are called operations dashboards. Staff end up ignoring most of them, sometimes 35 out of 40!
The issue with these useless metrics is not just that the screen looks cluttered. They also make the computer system work too hard. The best companies carefully check all their numbers. They ask a simple question for every piece of data: “What choice can we make because of this number?”
If they cannot find a good answer, they remove the metric. This smart approach actually cuts down the data load.
Predictive analytics replacing heavy historical pulls
Traditional queue systems would have to dig up six months of past information every time they wanted to guess what would happen later.
New age queue systems are much smarter. They use machine learning algorithms that have already studied those past patterns.
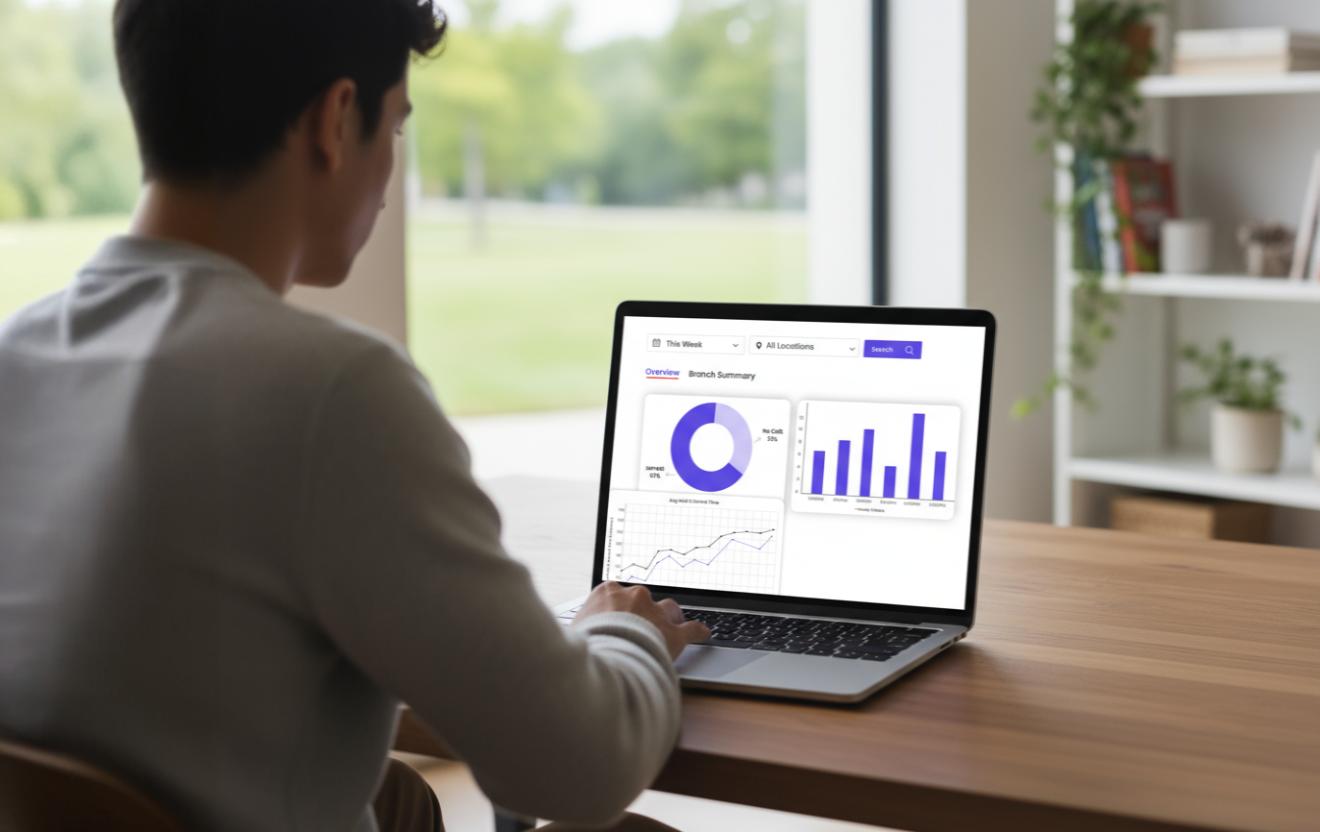
When you need to know the wait time for the upcoming day, the system just runs a quick prediction using its existing brain. It does not need to search the huge database again.
Consolidated dashboards that eliminate duplicate queries
In most organizations, different teams, from the operations teams, the managers, to the data groups, all ask the computer system for the same information. But they all use different tools to ask for it. Every single request hits the main computer system, or backend. When many staff members check their screens at the same time, it creates a fake heavy workload on the system.
A unified dashboard architecture fixes this. It means the computer system asks for the data only once. Then, it gets the data ready and sends it to everyone’s different screens.
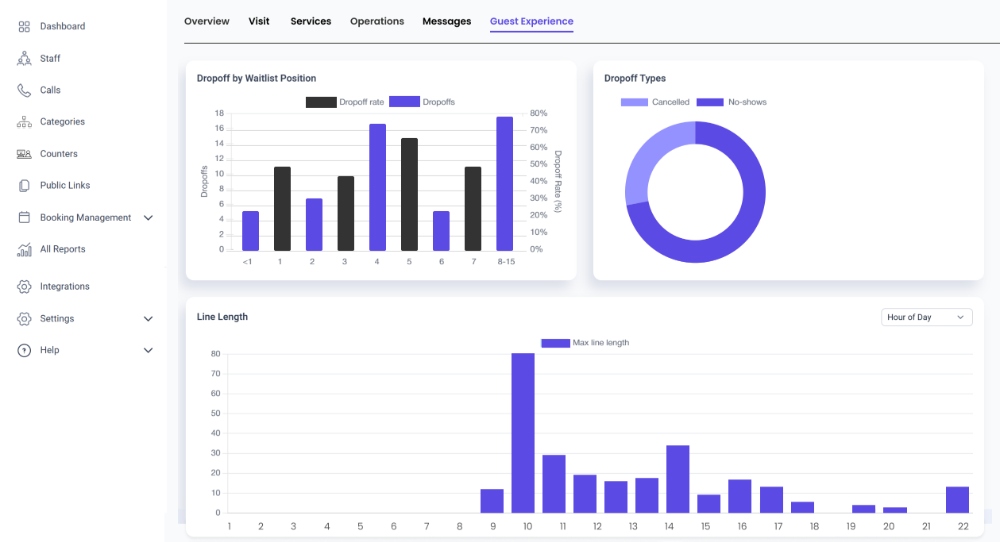
This simple change can cut the number of requests to the backend by 40% to 50%. People still see all the information they need, but the system works much less.
Here are the most common problems faced by businesses and how traditional and modern organizations solve them:
| Overload Point | Traditional Approach | How Leading Organizations Solve It |
| Duplicate Requests | Each department queries independently | Unified API layer serves all teams |
| Heavy Reports | Full data exports on demand | Pre-aggregated summaries with drill-down |
| Manual Pulls | Staff downloading CSVs repeatedly | Automated distribution on schedule |
| Multi-Team Data Demand | Separate tools for ops, analytics, management | Single source of truth with role-based views |
High-performing teams focus on a small set of queue metrics that actually drive decisions. If you want to know which metrics matter the most and how to implement them, you must read our blog:
Queue Management KPIs: 5 Metrics That Drive Operational Excellence
Real Strategies Enterprises Use to Balance Data Efficiency & Queue Performance
Theory is about ideas, but putting those ideas to work is what really matters.
Here is what companies are actually doing to make these changes happen in the real world:
Replacing isolated tools with a unified queue ecosystem
Most systems that manage waiting lines grew up piece by piece. They used different tools for appointments, people who walked in, online waiting, and text messages.
Each of those tools kept its own data record. This means the same information was saved many times, which created a huge amount of extra work. The main problem, though, is that the information was not always the same in every tool.
When companies switch to a single system, like Qwaiting, all the data goes through one design. Now, a customer who uses online booking, gets text messages, and checks in virtually is recorded as one piece of data, not four different ones.
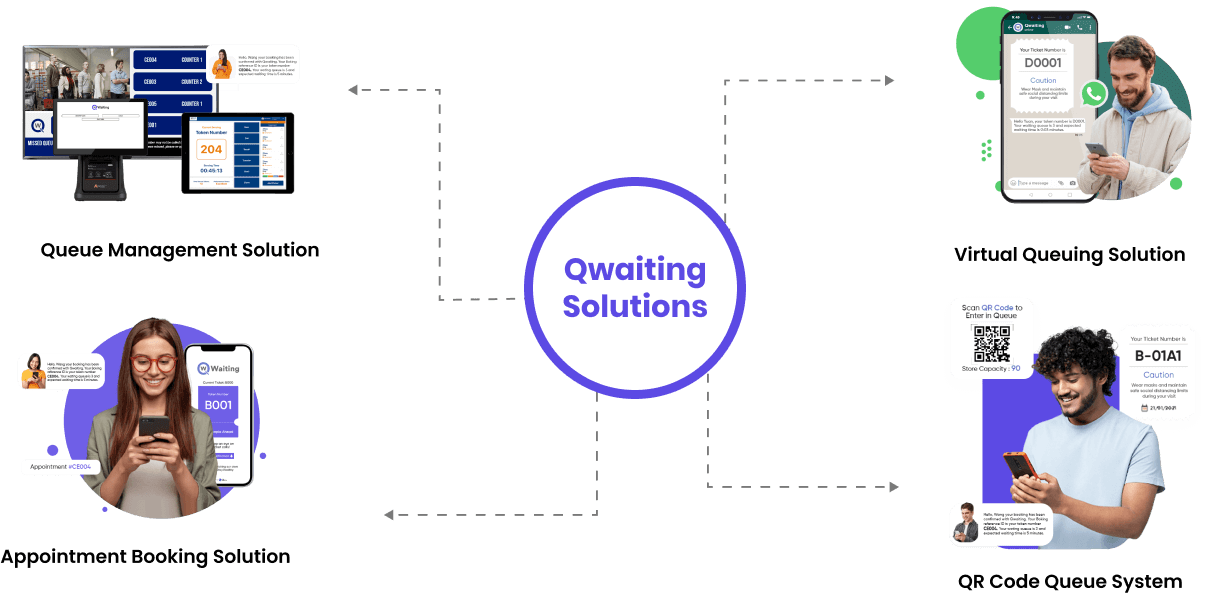
This stops the computers from doing extra, repeated work. It also makes sure that everyone, from the front desk to the manager, sees the same information at the same time.
Cloud-native scalability for peak-hour stability
Traditional on-premise systems are built to handle the busiest moment they will ever have. This means you have to pay for computers that just sit there and do nothing most of the time.
Cloud-native platforms can grow automatically. They quickly add more computer power during a very busy time. Then, they quickly shrink back down when things are quiet.

This saves money because you only pay for what you use. It also keeps the system fast and stable during those busy times. This means your waiting line system never slows down exactly when you need speed the most.
Messaging automation to reduce unnecessary refresh requests
Every time a customer uses their phone to check the waiting line status, the system automatically creates a query. In a busy store, these checks can cause 40% to 50% of all the requests the main computer gets.
SMS and WhatsApp messages change this completely. The system sends the updates to the customer automatically. This means the customer does not have to keep refreshing their screen to check the status.
Security & compliance gains from reduced data load

Most companies forget this important point: less data means fewer chances for hackers to cause problems.
Every piece of data you save that you do not need is another chance for a security issue. It all needs to be protected (encrypted) and have security checks.
Simple, small lean data systems make it harder for hackers to get in. They also make it easier to follow important rules like GDPR (for privacy). For places like government offices and hospitals, this is a huge deal. Having less data makes checking your systems easier and reduces the chances of private information getting out. All of this happens while the system runs faster, too!
The Future: Data-Light Queue Management Built for Global Scale
The trajectory is clear: organizations are moving away from data accumulation and toward data intentionality.
What leaders are moving toward
The next generation of queue management doesn’t look like current systems with more features, it looks fundamentally different.
- Leaner frameworks that process less while delivering more relevant insights.
- Faster refresh cycles that keep pace with customer expectations.
- Efficient, low-bandwidth operations that work reliably regardless of network conditions.
This shift is being driven by organizations operating at scale,
- Healthcare networks with 50+ locations
- Retailers managing holiday traffic across regions
- Government agencies serving millions annually
These operations can’t afford systems that slow down when it matters most.
The shift from ‘data-heavy’ to ‘data-intentional.’
Executives are starting to ask different questions in vendor evaluations. Instead of “How much data can this system capture?”, they’re asking “How quickly can this system deliver the insight I need to act?” It’s a fundamental change in what we value.
The most sophisticated operations leaders I work with talk about clarity rather than volume. They’re prioritizing insights that support scalability, metrics that work as well across 200 locations as they do for 20, and analytics that stay fast whether you’re serving 500 customers or 5,000.
Quick ROI Snapshot
Organizations implementing lean, event-driven queue architectures typically see:
- 52-68% reduction in server load and infrastructure strain
- 70-85% improvement in queue refresh speed and dashboard responsiveness
- 45-60% drop in customer “status check” requests and inquiries
- 18-32% uplift in service satisfaction scores within first 90 days
Conclusion
Here’s what you should ask about your current queue ecosystem: Is it designed for speed, or weighed down by unnecessary data? Are your systems processing what matters, or just processing everything?
The organizations winning on customer experience have figured out that queue performance isn’t about collecting more data; it’s about moving the right data faster. If your dashboards lag during peak hours, if your staff complains about system slowness, if customers are walking away because they’ve lost trust in queue accuracy, the problem probably isn’t your hardware.
Ready to see how data-efficient architecture changes queue performance? Explore how modern queue management platforms balance real-time visibility with system efficiency, or see the ROI impact for your specific operation.
Call our expert team today and start your 2-week free trial!